
我們提供全方位的網站服務,包括企業網站定位分析,網站規劃設計、網站建設、網站數據分析、移動端網站設計制作、微商城(微分銷)建設、域名注冊、通用網址、網站客服系統、等整套解決方案,

互聯網時代,對于每個企業來說官網都是很重要的,它直接 代表企業的形象,在互聯網上所占據的位置。從PC端的網站平臺搭建,到移動端的設計應用, 網站建設及推廣優化,如何讓用戶搜索并選擇自己至關重要。
1月6日召開的2017(第七屆)中國互聯網產業年會上發布《2016年中國互聯網產業綜述與2017年發展趨勢》,互聯網技術成為創新發展的強勁動力。數字化、智能化服務技術蓬勃發展;增強信用與安全的技術....

在互聯網飛速發展的環境下,信息的傳遞與反饋快速靈敏。我們著力為東莞、深圳及周邊上千中小型企業提供了互聯網全方位的服務,不論是品牌宣傳還是互聯網營銷方面都有著顯著的效果。

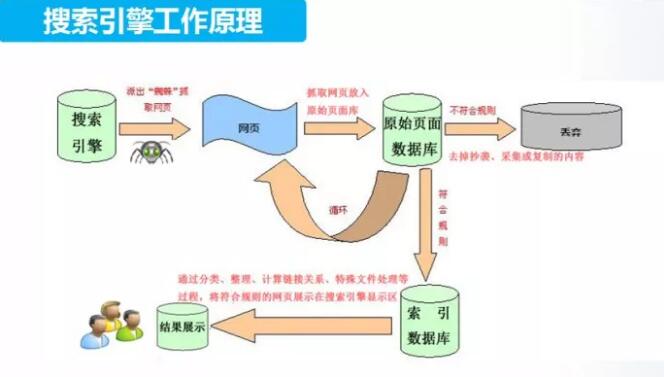
我們有著眾多的品牌服務經驗、獨到精準的設計創意及表現、贏得了眾多企業的認同與贊賞。為很多企業提供了很好的網站建設設計方案、搜索引擎自然排名方案、網絡品牌宣傳等等一系列全方位的網絡策劃方案...






 ??在線咨詢
??在線咨詢